- SUPPORT
- TECHNOLOGY SUPPORT
- AVAILABILITY
- HIGH AVAILABILITY
- TECHNOLOGY INFORMATION
- TECHNOLOGY WHITE PAPER
- Network Management Systems Architectural Leading Practice
Downloads
Introduction
Preface
Intent
Network Management Goals and Requirements
Operational Goals
Functional Requirements
Network Management Architectural Model
Hierarchical Approach to Network Management
Reducing Downtime (MTTR)
Silos
Manager of Managers
Automation
Inventory Management
Overlapping Managers
NMS Operational Dependencies
Auditing
Remediation
NMS Collection Stations
Hardware Redundancy
System Backup
Uninterruptible Power Supply
SNMP Community Strings
SNMP Polling Standards
NTP
DNS
Telnet/SSH
Glossary of TermsThis document is intended to provide the reader with a high-level guide to help establish a network management architecture that can be implemented as one the goals toward providing a world-class network and support infrastructure.
The document will detail the Advanced Services network management proposed strategy and how it relates to the ISO and IT Information Library (ITIL) management models.
Cisco ® uses both the functional fault, configuration, accounting, performance, and security (FCAPS) model as defined by the ITU standards and the ITIL framework to assess network management areas. ITIL references and terminology are used in this document. Specifically, this document incorporates several of the ITIL service management concepts. This document contains strategies regarding incident and problem management as they relate to the ITIL framework..
This document should help you focus on requirements based on the documented network management philosophy and an existing understanding of your network management objectives. It is a document intended to generate discussion between you and your team as to the most appropriate network management architecture for your company.
A viable network management solution must provide reliable, scalable support and effective visibility into your infrastructure. This document provides strategies and recommendations on the architecture and design for the network management systems that should support your business goals and objectives.
The completed product of the process started by this document should then act as the architecture guidelines for future network management system (NMS) tool selection, thus helping to ensure that independent implementations will not result in system incompatibilities and that critical network management integration will occur.
This document outlines a proposed high-level strategy of the key areas of network management architectures. The intent is to jointly review each section and create a final strategy that meets all listed requirements and supports your company's business goals. Once an area has been finalized through a joint review process, an associated set of lower-level documents may be created by your company's various stakeholders that will provide detailed designs and implementation plans as required.
Network Management Goals and Requirements
The functional requirements for the architecture outlined in this document are intended to allow your company to achieve the following operations goals:
• Proactive monitoring of network infrastructure and service levels
• Streamline network operations functions through NMS tools optimization
• Scalability of NMS architecture to support new network technologies such as Multiprotocol Label Switching (MPLS), wireless, quality of service (QoS), and others
• Increase the ability to detect soft failures at the protocol, hardware, system software, and interface levels
• Help enable proactive maintenance to be performed by the network operations center (NOC) support team upon detecting faults or performance degradation
• Help enable intelligent forwarding of network events to the NOC
Given the high-level manageability goals outlined above, the following sections highlight the functional requirements in specific network management functional areas.
Fault management encompasses the discipline of identifying faults in a network environment. Faults are identified by receiving events such as syslog and Simple Network Management Protocol (SNMP) traps from network devices, polling network device MIBs, and identifying real or potential error conditions and setting thresholds that trigger events. In addition, the NMS should be able to provide event correlation as well as reporting and tracking. The NMS used should also provide a northbound interface for exporting critical messages to a higher level manager or MoM (manager of managers).
In an ideal environment, the fault manager would collect both syslog and SNMP information, filter that information, and pass the filtered data to a MoM for further processing. This method helps decrease the amount of data that an end user needs to see or react upon. The MoM, in turn, can provide further analysis and automation based on the incoming event streams such as verifying down circuits, testing connectivity, and opening trouble tickets based on those findings.
Stand-alone fault managers are used to gather event data from devices throughout the network and report their findings. They have little to no capability of automating reactions based on gathered data. When a message comes into the fault manager, the typical course of action is simply to report the fault to a screen being monitored by operations personnel.
By employing the use of a MoM, your system can react to these events automatically, which can drastically reduce downtime in mission-critical networks. For example, when an event comes in from the fault manager, the MoM can:
• Verify connectivity to the reported down device/interface by ping/Telnet or other means
• Gather information about the device such as vendor, serial number, location, contact information, circuit IDs, site IDs, and so on from a device inventory database
• Attach historical reports gathered from other NMSs such as bandwidth, CPU, memory, and so on
• Open a trouble ticket automatically and have that ticket prepopulated with important information from the device information database
This method would not only relieve operations personnel from having to look up the information for an outage, but would save critical time in bringing the fault to a resolution.
Event management encompasses event-correlation and root-cause analysis. It allows for multiple input streams from various network devices and environments and, using knowledge of the network topology and a sophisticated rule set, attempts to identify the source or root cause of a network fault or problem.
• At the top level (MoM), event correlation features should be supported to aggregate and correlate incoming alarms. The system needs to have the intelligence to correlate event types (SNMP, syslog, and so on) as well as to provide automation of tasks based on event criteria.
• Filtering capability should be supported to selectively display relevant alarms.
• The system should be capable of escalating critical alarms based on the number of occurrences and time delays in acknowledgement.
• Alarm severity should be customizable based on end-user or operational needs.
• Alarm properties and escalation should be policy based, dependent on the role of the device in the network.
• The system should be able to virtually partition the managed network into multiple logical entities based on geographical locations.
• The fault management system should support role-based access to fault events based on job responsibilities.
• A knowledge base consisting of troubleshooting guidelines or methodologies should be part of the fault management system. This is to facilitate rapid problem isolation on network-related issues.
• The system should provide integration between the fault and the inventory management system to support autopopulation of information.
• Integrate between the inventory system and the trouble-ticketing system for autopopulation of relevant trouble ticket fields.
• The system should provide the flexibility to forward traps and alarms to a different location/system for after-hours monitoring.
Log Management (Syslog)
Logging is a critical part of network management. Good logs can help you find configuration errors, understand past intrusions, troubleshoot service disruptions, and react to probes and scans of your network. Cisco devices have the ability to log a great deal of their status.
Syslog is also a great resource for network compliance, allowing companies to adapt quickly to changing regulations such as Sarbanes Oxley (SOX), Control Objectives for Information and related Technology (COBIT), IT Infrastructure Library (ITIL), Gramm-Leach-Bliley Financial Modernization Act (GLBA), Visa Card Holder Information Security Program (Visa CISP), Payment Card Industry (PCI) Data Security Standards, Health Insurance Portability and Accountability Act (HIPAA), Committee of Sponsoring Organizations (COSO) of the Treadway Commission, and custom regulations.
Defining all aspects of a syslog server is outside the scope of this document.NMS North and Southbound API Interfaces
Communication between multiple network management systems is extremely important for event correlation and data aggregation. Most, if not all, NMSs should be able to communicate bidirectionally. This helps ensure the ability to provide correlated events as well as the coordination of data sources throughout the network such as inventory, access, performance data, and so on.
Network Management Architectural Model
Hierarchical Approach to Network Management
Layering of network management not only allows NMS systems to communicate better, it reduces the amount of alerts seen by network operations support staff. At the lowest layer, it is nearly impossible to keep up with events displayed from each network element reported in the NMS architecture. For example, it is not feasible to have someone watching every syslog event that occurs on the network. Instead, you rely on systems at the Network Management Layer (NML) to filter through all events and show only those events deemed as most important. The Service Management Layer (SML), meanwhile, is used to further summarize events from the NML and tie multiple network management systems together. A good NMS system will also provide deduplication of these network events in order to further reduce the amount of unnecessary messages seen by operations personnel.
The hierarchical model in Figure 1 shows the major components that make up a comprehensive NMS system and provides a high-level integration scenario. Cisco Advanced Services encourages the adoption of a layered, hierarchical network management system. This type of architecture involves data flow and integration of multiple NMS tools to be effective. Figure 1 depicts those tool and data relationships.
Figure 1. Hierarchical Model Overview
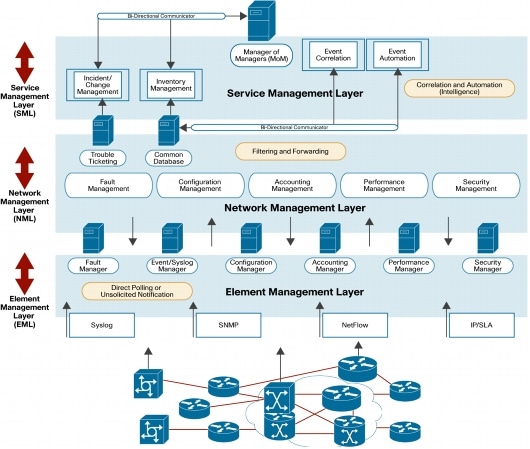
The underlying hierarchical philosophy is to get the organization to a basic level of integrated network management. The foundation for this architecture comes from the Telecommunications Management Network (TMN) (M.3000) model. "TMN provides a framework for achieving interconnectivity and communication across heterogeneous operations system and telecommunication networks. To achieve this, TMN defines a set of interface points for elements which perform the actual communications processing (such as a call processing switch) to be accessed by elements, such as management workstations, to monitor and control them. The standard interface allows elements from different manufacturers to be incorporated into a network under a single management control." ( http://en.wikipedia.org/wiki/Telecommunications_Management_Network ).
Element Management Layer
The first level, the Element Management Layer, defines individual network elements used in deployment. In defining this layer, for each anomaly that occurs in the network, potentially multiple devices can be affected by the event and can independently alert network management systems that an event has occurred resulting in multiple instances of the same problem.
Network Management Layer
In the middle of the diagram is the Network Management Layer. This function takes input from multiple elements (which in reality might be different applications), correlates the information received from the various sources (also referred to as root-cause analysis), and identifies the event that has occurred. The NML provides a level of abstraction above the Element Management Layer in that operations personnel are not "weeding" through potentially hundreds of Unreachable or Node Down alerts but instead are focusing on the actual event such as, "an area-border router has failed."
Service Management Layer
At the top of the diagram is the Service Management Layer. This layer is responsible for adding intelligence and automation to filtered events, event correlation, and communication between databases and incident management systems. The goal is to move traditional network management environments and the operations personnel from element management (managing individual alerts) to network management (managing network events) to service management (managing identified problems).
Benefits of Hierarchical Layers
From a practical perspective, integrating these elements involves:• Assembling a robust set of event correlation rules that consistently and accurately identify the source of an event
• Opening a trouble ticket in an incident management application that operational personnel begin working on
This helps enable an operations organization to:• Proactively manage the network
• Identify and correct potential network issues before they become problems
• Prevent a loss of network connectivity, thus ensuring organizational productivity
• Focus on the solution instead of the problem
Reducing Downtime (MTTR)
Most of the tools deployed in traditional NMS environments act as "silos" meaning they are not aware of any other tools available within the environment. Some of the issues resulting from this design include seeing multiple alarms for single events, looking too many places for event information and creating a disconnect of information between network events and support personnel resulting in lost information and Mean Time to Repair (MTTR).
Manager of Managers
A MoM is instrumental in providing the intelligent network management services at the top layer of this hierarchical model. Among other things, MoMs are used to provide a final filter between the network operations personnel and events seen on the network. The MoM can correlate events to other sources of information (such as inventory, performance, contacts, and so on) and provide automation for operational tasks that can greatly decrease MTTR.
Automations should be implemented for common events and tasks. These automations should be triggered by the MoM and are designed to reduce MTTR.
For example, when an event comes in, most operations personnel are trained to perform certain tasks before ever actually working on the event. These tasks may include verification of the outage (by manually pinging, and so on), looking up contact information (who owns that device), deciding how important the device is according to when the event happened (3 a.m. on Sunday, nonessential device, versus 1 p.m. on Monday, and so on).
All of these procedures can be automated so that when an event comes in, operations personnel are presented with final results of gathered information instead of the simple event. Tables 1 and 2 show a simplified example of such an event stream. Note that this is merely an example; there are many other items that can be prepopulated to event lists.
AUTOMATION EXAMPLETable 1. Event Automation: Simple Event

- TECHNOLOGY WHITE PAPER
- TECHNOLOGY INFORMATION
- HIGH AVAILABILITY
- AVAILABILITY
- TECHNOLOGY SUPPORT